Social networks extracted from movies or series are interesting research material. You can either download them (via pages like Moviegalaxies) or create them yourself (e.g. using our tool ezlinavis). They are also well suited as a basis for tool-based introductory courses in network analysis.
Often, however, we don’t know exactly how the data came about (for example, there is still the problem that Frodo appears twice in the network extracted from the first of the three “Lord of the Rings” movies on Moviegalaxies – how did that happen?). Another problem is that sometimes it just takes too long to extract your own network data in a scene-by-scene fashion using ezlinavis.
So it might come in handy if we introduce another way to retrieve network data.
If you happen to have an Amazon Prime Video account (or know someone who has 😊), you may have noticed the X-Ray feature. When you press the ⏸️ button, you see background information about the current production, including information about the characters/actors currently on screen.
Turns out that this information is stored in a JSON file that you can download for each movie/series in a roundabout way. Once you have this file, you can do some analysis with it, like visualising the screentime of characters or extracting co-presence networks, which is really neat. (One advantage is that you can very easily compile datasets on your own favourite movies or series, so long as these productions are available on Prime Video.)
To start with a visual argument, here is the result for Sam Mendes’ movie “1917”, followed by a description of how we did it:
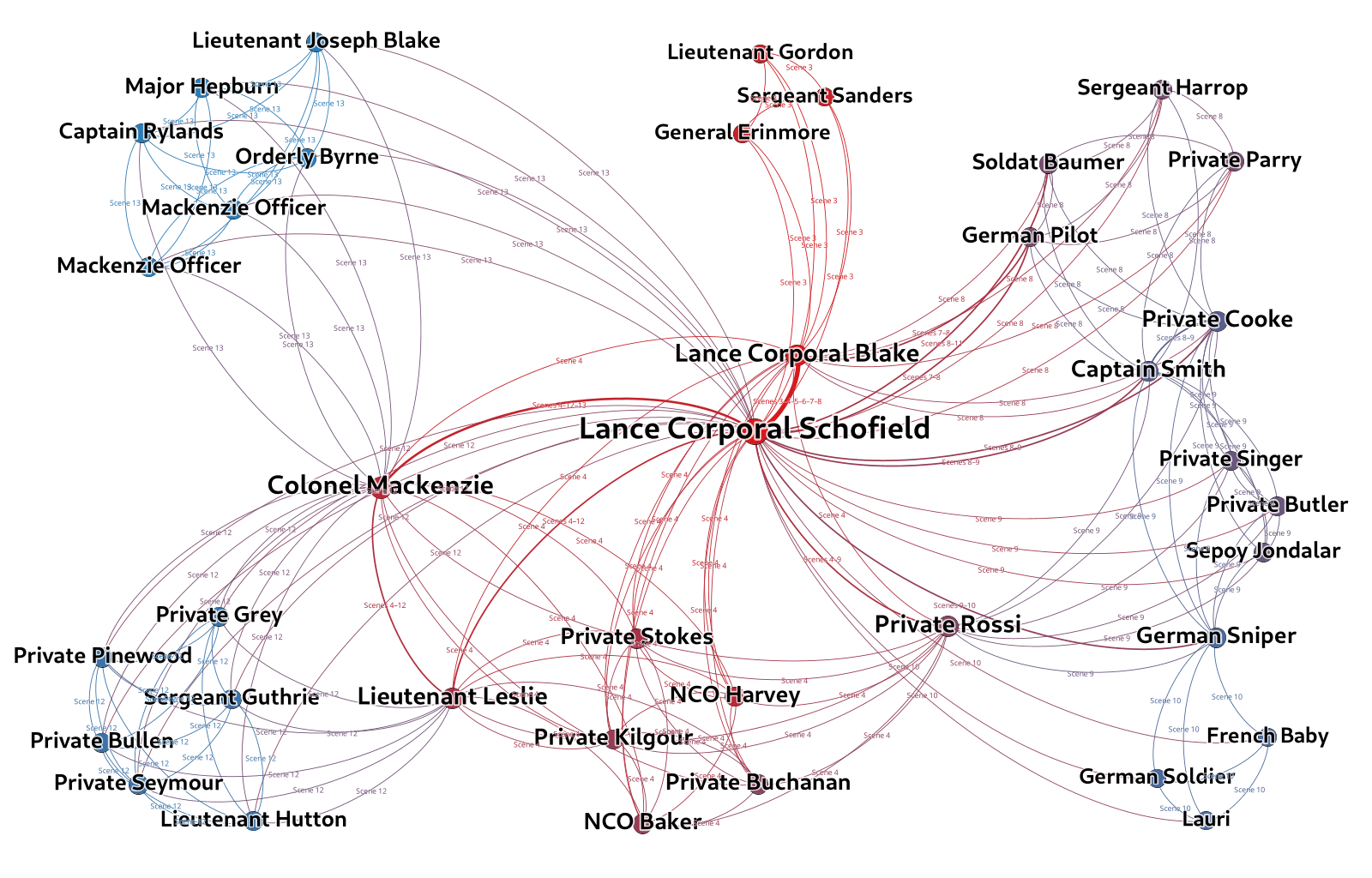
We are far from being the first to discover this possibility. In fact, there’s a blog post from 2016 on this topic – and although things usually change all the time on the internet, the method described still works almost 6 years later.
The first step is to download the JSON file using your browser’s built-in developer tools.
The resulting JSON file is a bit convoluted, but it is relatively easy to find your way around it. Amazon’s X-Ray data divides the entire movie into 14 scenes ("id":"/xray/scene/1" etc.):
| Scene | Starts at |
|---|---|
| 1 | 00:00:00 |
| 2 | 00:00:48 |
| 3 | 00:01:01 |
| 4 | 00:11:21 |
| 5 | 00:16:29 |
| 6 | 00:25:45 |
| 7 | 00:30:50 |
| 8 | 00:44:37 |
| 9 | 00:54:57 |
| 10 | 01:06:33 |
| 11 | 01:19:56 |
| 12 | 01:22:59 |
| 13 | 01:38:20 |
| 14 | 01:49:32 |
These scene divisions are, of course, contingent and can also lead to rather poor results for some movies. But for “1917”, a station drama, it works quite well.
Let’s look at Scene 6, which features only two characters, Schofield and Blake:
{
"changesCollection":[
{
"changeType":"AddItem",
"itemId":"/name/nm1126657/Lance Corporal Schofield",
"timePosition":1548000
},
{
"changeType":"AddItem",
"itemId":"/name/nm2835616/Lance Corporal Blake",
"timePosition":1560000
}
],
"initialItemIds":[],
"timeRange":{
"endTime":1850000,
"startTime":1545000
}
}
As you can see, in addition to the mere co-presence in a scene, there is also a temporal marker for the appearance of a character. But if you think this would make it easy to measure the overlap of the presence of two characters, alas, no. Because, unfortunately, there are only markers for their entrance, not their exit, so a character is always “present” until the end of a scene.
To extract the co-presence network data, we wrote a little Python script (based on the example here). We also included shared scenes as edge labels and fed all this into Gephi, the result of which you have seen above.
Conclusion
We don’t know how Amazon Prime’s X-Ray data is encoded in practice, so we can’t assume that all JSON files were created in a similar process. But the fact that we can read this JSON data relatively easily, despite the lack of documentation, allows us to do some meaningful things with it.
And there’s a lot more we could do with the X-Ray data. For example, the JSON also contains IMDb IDs of actors (e.g. "id":"/name/nm1126657/Lance Corporal Schofield" → imdb.com/name/nm1126657/). But for now, as Ed Wood used to say so enthusiastically, that’s a wrap!

