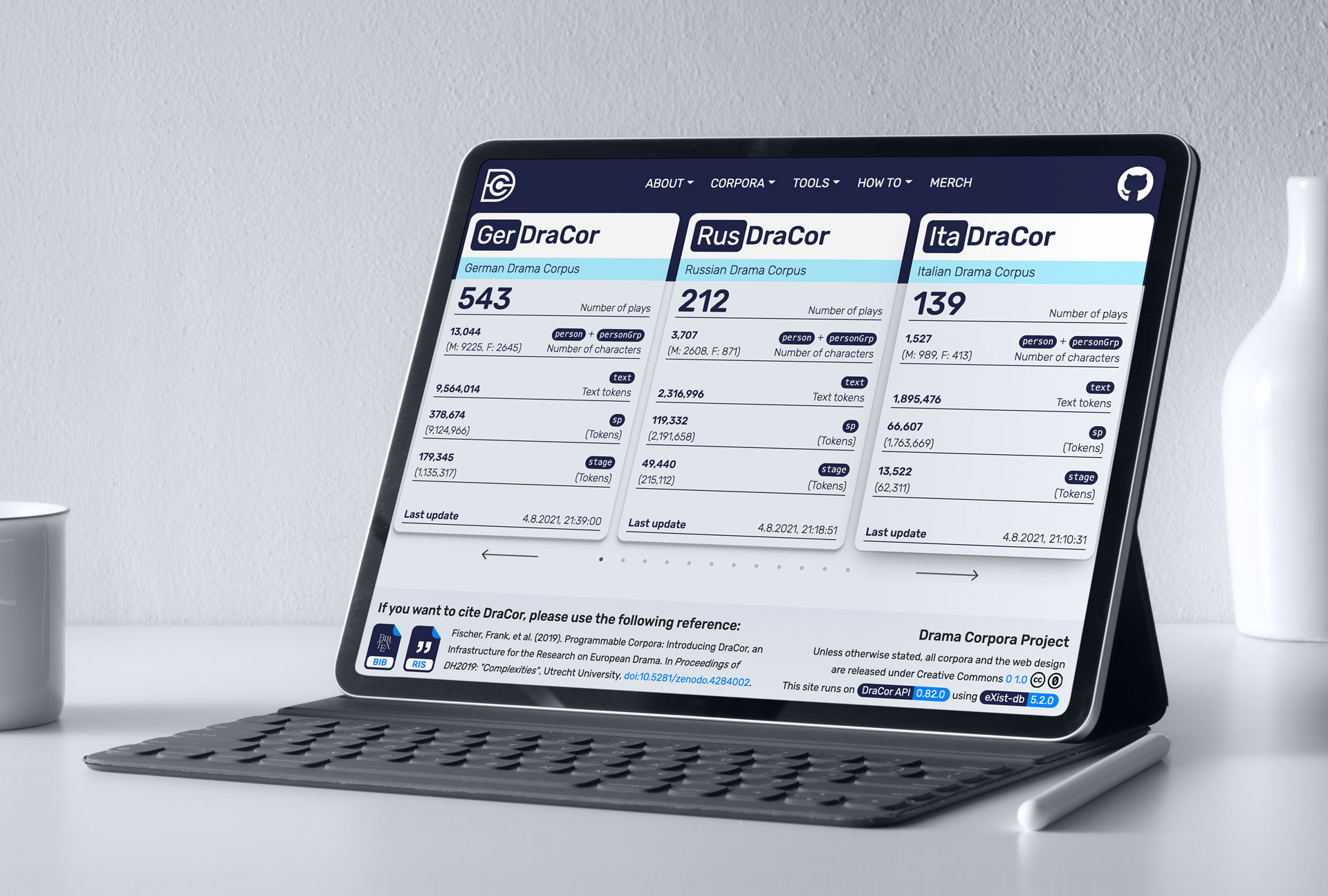
DraCor, the Drama Corpora platform, can be accessed at dracor.org. Our aim is to provide an infrastructure component for computational literary studies in order to facilitate access to relevant research data and to ensure compliance with the FAIR Principles when dealing with literary corpora. In our case, the focus is of course on drama and theatre, but we plan to extend our concept of Programmable Corpora to novels as part of the H2020-funded CLS INFRA project that started earlier this year.
Today, we are pleased to introduce the next iteration of our DraCor website, along with new API functions that make it much easier to access our data for research. Our front-end, i.e. web design, is now at version 1.1.0, the DraCor-API at version 0.82.0.
We have worked on all levels of the website, the homepage, the corpus overviews and pages of individual plays:
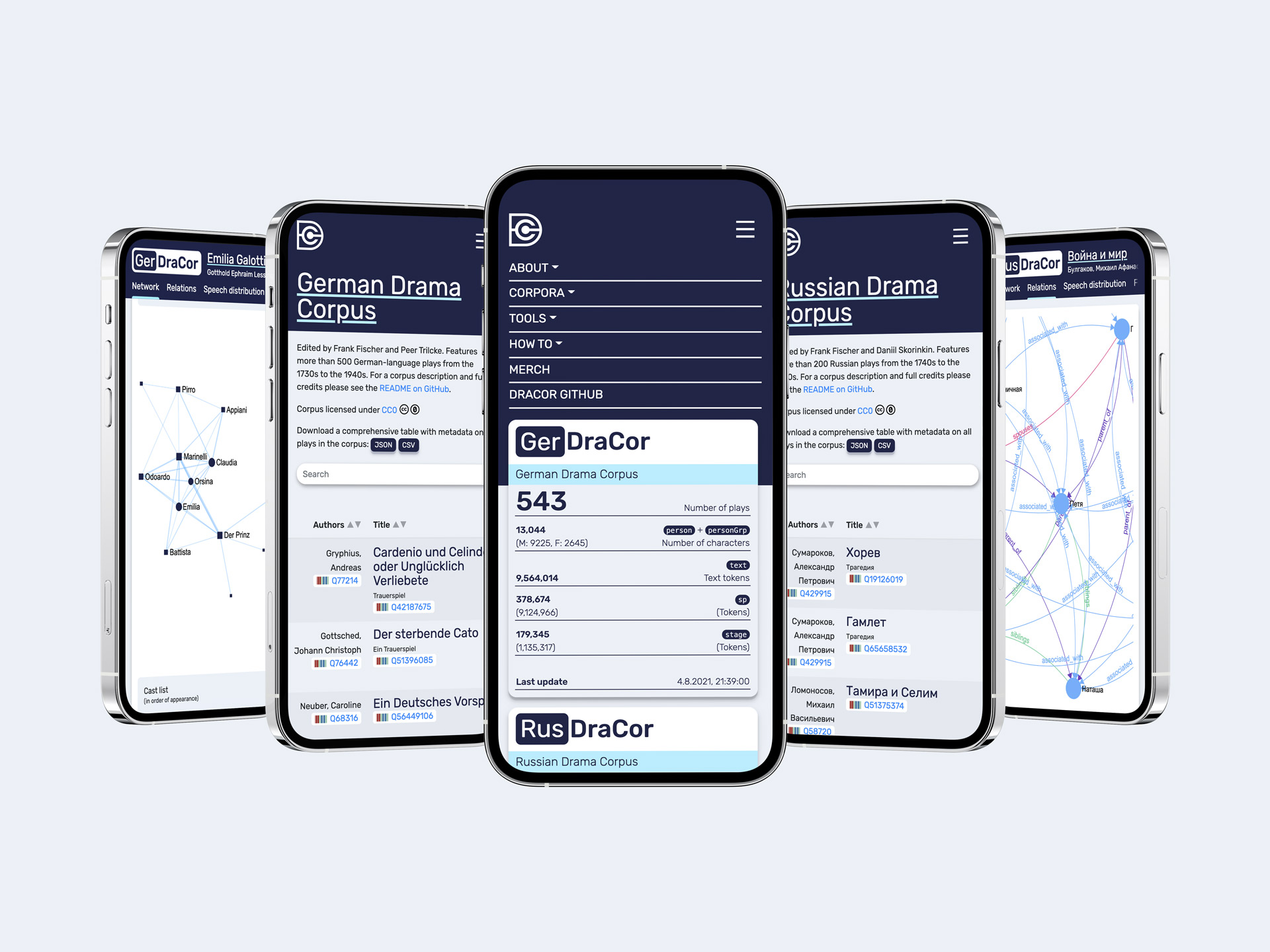

As before, the website should work well on all types of devices, large screens, laptops, tablets and mobile phones. There are many small details to discover in the new design (our favourites are the author images that we automatically retrieve from Wikimedia Commons via Wikidata QIDs, just one small example of the benefits of our highly interoperable approach).
The overall design is even better aligned with the TEI encoding on which all our corpora are based to increase the visibility of our rich annotations.
Here’s a non-exhaustive summary of the new functions added since December 2020:
- infoboxes are now context-sensitive (their content differs depending on which tab is activated: “Network”, “Relations”, “Speech distribution”, “Full text”, or “Downloads”)
- more explanations on the spot, e.g. the “Network” tab is accompanied by a short description of what the network graph actually shows
- we also introduced an ℹ️ symbol that leads to longer explanations in our newly introduced (and still somewhat empty) FAQ section
- author information and images sourced live from Wikimedia Commons via Wikidata identifiers
- improved readability of network graphs (annotated information on gender is now integrated, colour contrast has been increased)
- plays with historical or mythological characters now display a Wikidata QID if available, a new feature provided by our API (not all corpora are yet encoded with this information, but once they are, it will be much easier to compare all plays with e.g. a Faust character or to do a contrastive analysis of the vocabulary of mythological and historical characters in different authors and even between corpora in different languages)
- the “Full text” tab now shows the print source in the context box, along with an overview of speaking characters per segment
- corpus metadata is now much more accessible, you can download it directly from the corpus overviews (try the CSV version to create some quick charts in MS Excel or LibreOffice Calc)
- added a button to copy DraCor IDs to the clipboard
- new corpus added: BashDraCor
- new plays were added to our in-house corpora, GerDraCor and RusDraCor
- Michael Sonkin added numerous character annotations to ItaDraCor, significantly improving the corpus which we originally inherited from Biblioteca Italiana
- introduction of TypeScript (to gradually improve the quality of our codebase)
Ok, we’ll stop here. As always the complete history of changes can be traced on GitHub.
How Did We Get Here?
Our React-powered website and the DraCor API have been up and running since 2017. We started with a German and a Russian drama corpus, both encoded in TEI, but later added many more corpora, a handful of which were provided by the community. At the moment we host 12 active drama corpora, and number 13, the rather large French Drama Corpus (more than 1,500 plays so far), is just around the corner. Many colleagues have approached us asking if they can add their corpus in the future, and we very much welcome their contribution. (If you have or want to create or maintain a TEI-encoded drama corpus and add it to DraCor, please drop us a line.)
Looking back, we find it hard to believe that we didn’t initially intend to run a fancy website at all, our focus was on functionality. It wasn’t until we had developed the concept of Programmable Corpora and the website was functional and running stably that we eventually decided we wanted a fancy website too. So in December 2020, we released version 1.0.0 of the DraCor front-end, and since then the project has received much more attention. In the past it wasn’t a big problem when DraCor went offline on a Friday afternoon because of an unexpected server error, we just fixed it the next week. Well, we can’t wait that long anymore. 😊 Now we try to fix a problem as soon as it arises. If this isn’t possible, we collect more complex issues (and also feature suggestions) in the issue tracker.
Another way to measure our impact is through the increasing number of third-party research conducted with our data. The most recent example is Inna Wendell’s PhD thesis at UCLA on Russian five-act comedy in verse. A growing list of DraCor-enabled research can be found on our website. We also just set up a Zotero collection to keep track.
API
DraCor is of course more than a website, as we never tire of pointing out. The crucial element is its API. All currently active functions are documented via Swagger, but this is of course not enough, especially if you are not yet that used to dealing with APIs. We are planning some workshops in the near future to train how to use the API so that the TEI-encoded DraCor corpora can unleash their full power to answer research questions. Stay tuned.
Ways of Interaction
I’m sure we’ve forgotten this or that detail in this blogpost, but hope you enjoy exploring the new DraCor. If you run into an issue, have a question, or want to contribute, you can always check our Credits page to find the right contact person. We also use the GitHub Discussions feature for the dracor-frontend repo (all things website) and dracor-api (all things API functionality).
That’s it for today. It’s been great to do some hacking together over the last months, even if the infamous in-person Potsdam/Moscow hackathon spirit is still unmatched. See you soon.
🌞 🌴 🐬 ⛱️


