Our last blogpost on Vossian Antonomasia (VA, or, vossanto) appeared almost two years ago. Since then, we were busy improving our methods, writing papers, and updating our web page with some more data to explore. In this article we summarise the latest developments.
Interactive Timeline for Data Exploration
In the past year, our research group at IBI conducted a small code sprint to create an interface for the visual exploration of Vossian Antonomasia extracted from our New York Times working corpus (covering the years 1987–2007). Thanks to Sjaak Priester and his excellent JavaScript Dateline widget we were able to quickly set up an interactive timeline:
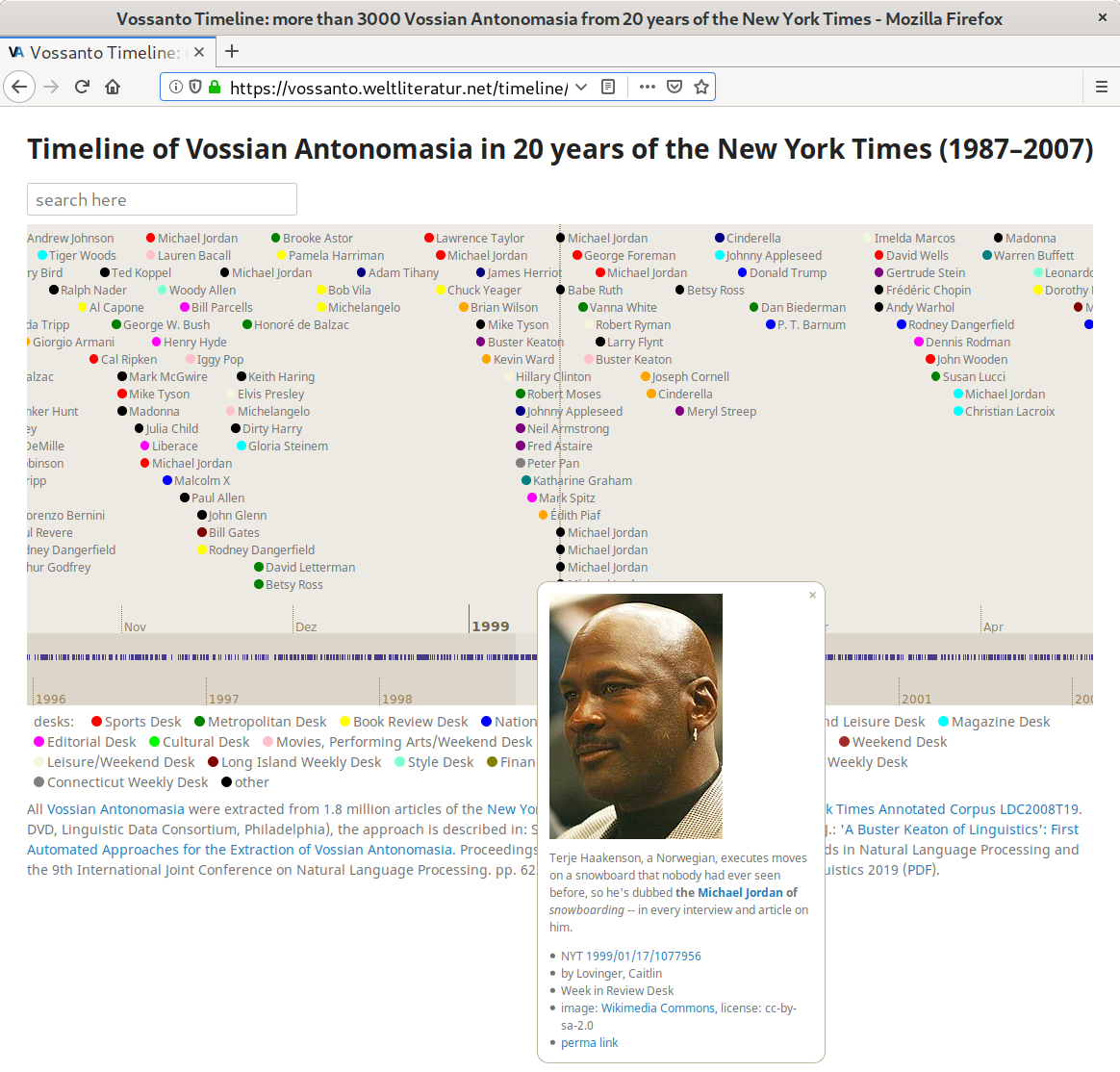
It assembles all Vossian Antonomasia extracted with the method described in our 2019 EMNLP-IJCNLP paper. Each VA is represented by a colour dot and the named entity providing the source (whose properties or qualities are transferred to another named entity by the magic of Vossian Antonomasia). The colour of the dot indicates the New York Times desk responsible for the corresponding article. Clicking on an entry will display more information, as shown in the above screenshot:
- a photo automatically retrieved from Wikimedia Commons (if available),
- the sentence containing the VA expression with source and modifier highlighted,
- the article ID with a direct link to its full text,
- the name of the author,
- the name of the desk,
- source and licence for the photo,
- a permanent link to the corresponding VA expression.
Feel free to scroll through the timeline or just follow this example.
In the upper left corner you can find a box for full-text search. After typing in a few letters it shows all matching VA expressions. Clicking on a match scrolls to the corresponding place in the timeline and shows the details, a very convenient way to find interesting Vossian Antonomasia. For example, type in “literature” to acquaint yourself with “the Tupac Shakur of American literature” or “the Madonna of Cuban literature”.
Automatic Detection of Vossian Antonomasia
Our first approach to VA extraction (published in Digital Scholarship in the Humanities 35.1, April 2020) was semi-automated, sentence-based, and strictly centered around humans. We used regular expressions to extract all sentences featuring our VA source pattern “the ENTITY of”. Then our core idea was to use Wikidata as knowledge base for distant supervision. We only kept candidates that included the exact name or alias of a Wikidata entity which had to be an instance of the class human. We used a manually created blacklist to exclude candidates like “the House of” (for ‘House’ being, among other things, a documented alias of botanist Homer Doliver House).
In our 2019 EMNLP-IJCNLP paper we automated the process of extracting VA from large newspaper corpora and compared three new approaches to our initial approach:
- The second approach is an extension of our previous method. We replaced the manually curated blacklist with a popularity measure to identify candidates that could be removed after linking an entity to a Wikidata entry. We compared the ‘popularity’ (for which we took the number of Wikidata sitelinks per entity) of a human entity to another entity featuring the same label. For example, the human entity ‘House’ (the botanist) only has 9 sitelinks while the entity ‘House’ (the building) has 178 sitelinks. We removed such candidates since it was unlikely that the label was linked to the correct entity. We also removed all candidates where the source (e.g., ‘Prince’) together with multiple subsequent words (e.g., ‘of Wales’) matched the name or alias of another Wikidata entity. This allowed us to get rid of frequent false positives like the Prince of Wales (who, grammatically, could also be an aspiring Welsh singer reminding of the Artist Formerly Known as Prince).
- Since we focus on people as VA sources, our third approach is based on named-entity recognition (NER). Instead of using Wikidata to detect sentence candidates, we now tried the Stanford NER tool to detect entities. We also applied the last step from the first approach to detect false positives.
- In our fourth approach we leveraged the annotations from our initial approach to train a neural network. First, we transformed each word of a sentence into a word vector using pre-trained word embeddings (GloVe). Then we fed the vectors into a neural network – a bi-directional long short-term memory layer (BLSTM) with a feed-forward layer – to let it learn to distinguish sentences that do contain a VA expression from those that don’t.
In our case, evaluating the different approaches is especially tricky due to the rarity of the phenomenon. It is unfeasible to determine the recall for the 1.85 million articles in our NYT corpus. Therefore we calculate precision, recall and f1 based on the labelled corpus. The BLSTM performs best, boosting the precision to 87%:
| approach | precision | recall | f1 |
|---|---|---|---|
| 1st: semi-automated | 49.8% | – | – |
| 2nd: Wikidata | 67.3% | 93.0% | 78.1% |
| 3rd: NER | 71.8% | 81.3% | 76.2% |
| 4th: BLSTM | 86.9% | 85.3% | 86.1% |
We are currently working on various approaches to detect all three parts (source, target and modifier) of a VA expression in a sentence. As a by-product, we will have an enriched corpus where all parts of a VA expression are tagged in each positively labelled sentence.
Modifiers
Since we need labelled data to train and evaluate our machine-learning approaches, we examined more than 3,000 VA expressions to annotate their targets and modifiers. As a result, we can now present more reliable statistics on the most common modifiers in our corpus. The ten most frequent modifiers are:
| count | modifier |
|---|---|
| 56 | his day |
| 34 | his time |
| 29 | Japan |
| 17 | China |
| 16 | tennis |
| 16 | his generation |
| 16 | baseball |
| 14 | her time |
| 13 | our time |
| 13 | her day |
A longer list with many more results can be found on our most recent statistics page. As described in our first paper, this list illustrates an important function of antonomasia, which is the “inculturation” of lesser known phenomena (cf. also Holmqvist/Płuciennik 2010, p. 379).
By filtering the modifiers we can create rankings for specific categories; for example, countries …
| count | country |
|---|---|
| 29 | Japan |
| 17 | China |
| 10 | Brazil |
| 8 | Iran |
| 7 | Mexico |
| 7 | Israel |
| 7 | India |
| 4 | South Africa |
| 4 | Poland |
| 3 | Spain |
… or sports:
| count | sports |
|---|---|
| 16 | tennis |
| 16 | baseball |
| 11 | hockey |
| 10 | basketball |
| 8 | golf |
| 8 | football |
| 6 | soccer |
| 6 | racing |
| 3 | women’s basketball |
| 3 | sailing |
| 3 | auto racing |
| 2 | pro football |
| 2 | New York baseball |
| 1 | Yale football fame |
| 1 | women’s hockey |
| 1 | women’s college soccer |
| 1 | this year’s national collegiate basketball tournament |
| 1 | the tennis tour |
| 1 | the tennis field |
| 1 | the soccer set |
| 1 | the racing world |
| 1 | the Olympic hockey tournament |
| 1 | stock-car racing |
| 1 | Rotisserie baseball |
| 1 | pro football owners |
| 1 | professional basketball coaches |
| 1 | professional basketball |
| 1 | motocross racing in the 1980’s |
| 1 | micro golfers |
| 1 | major league baseball |
| 1 | Laser sailing |
| 1 | Japanese baseball |
| 1 | Iraqi soccer |
| 1 | horse racing |
| 1 | hockey in the former Soviet Union |
| 1 | hockey commentary |
| 1 | high school baseball in New York |
| 1 | harness racing |
| 1 | golf criticism |
| 1 | football teams |
| 1 | football owners |
| 1 | football announcers |
| 1 | European hockey |
| 1 | country-club golf |
| 1 | college football underclassmen |
| 1 | college football these days |
| 1 | college football |
| 1 | college basketball |
| 1 | Chinese baseball |
| 1 | Brazilian basketball for the past 20 years |
| 1 | BMX racing |
| 1 | biddy basketball |
| 1 | basketball announcers |
| 1 | basketball analysts |
| 1 | basketball analysis |
| 1 | baseball’s new era |
| 1 | baseball managers |
| 1 | baseball executives |
| 1 | baseball collections |
| 1 | baseball cards |
Most modifiers are short and consist of only one to three words, as this plot of the distribution of the length (number of words) of modifiers shows:

The longest modifier we have found so far contains 25 words:
“And while he modestly demurs, Mr. Barker is widely regarded as the Bob Fosse of the carefully choreographed event that consumes Midtown Manhattan with tin whistles, step dancers and some two million spectators on that invariably brisk March 17 morning.” (source: 2001/03/07/1276052)
JSON Data Dump
As additional outcome of the timeline, our dataset is now also available in JSON format. The enriched JSON data dump contains links to Wikidata and to images of VA sources on Wikimedia Commons (including licence information), so that they can easily be reused for further analysis or demos. The following excerpt shows a JSON entry for an exemplary VA expression:
{
"id": "0039183_0",
"date": "1987-05-10",
"sourceId": "Q9696",
"sourceLabel": "John F. Kennedy",
"sourceImId": "John_F._Kennedy,_White_House_color_photo_portrait.jpg",
"sourceImThumb": "thumb/c/c3/John_F._Kennedy%2C_White_House_color_photo_portrait.jpg/180px-John_F._Kennedy%2C_White_House_color_photo_portrait.jpg",
"sourceImLicense": "pd",
"fId": "1987/05/10/0039183",
"aUrlId": "9B0DE3DD1E3EF933A25756C0A961948260",
"text":
"In the 60's Mr. Bernstein looked like *the John F. Kennedy of* /culture/.",
"author": "Botstein, Leon", "desk": "Book Review Desk"
}
The fields contain the following information:
| key | content |
|---|---|
| id | A unique (within the dataset) identifier for a VA expression. |
| date | Publication date of the corresponding NYT article. |
| sourceId | The Wikidata ID of the VA source. |
| sourceLabel | The (English) Wikidata label of the source. |
| sourceImId | The name of the source’s image on Wikimedia Commons. |
| sourceImThumb | The path to the source’s image on Wikimedia Commons. |
| sourceImLicense | The licence of the source’s image. |
| fId | The ID of the article’s file in the NYT dataset. |
| aUrlId | The ID of the article as part of its URL (http://query.nytimes.com/gst/fullpage.html?res=<HERE>) |
| text | The sentence containing the VA expression (including org-mode markup). |
Future Endeavours
We are very interested in analysing Vossian Antonomasia in languages other than English (especially German) and are looking for suitable corpora. In general, our aim is to better understand Vossian Antonomasia and its usage, distribution and variety.
As always, all details can be found on our project website https://vossanto.weltliteratur.net/.


