The first challenge we face when trying to analyse the representation of world literature on Wikipedia is the automatic identification of literary writers and works across all 280+ language versions. Our last posts have shown how to extract works that are possible candidates for a Wikipedia-inherent world-literary canon (Wikidata-based and DBpedia-based). In this 2-part post we focus on the extraction of writers, i.e., possible contributors to world literature.
For a start, let us have a detailed look at the Wikipedia page of John Irving:
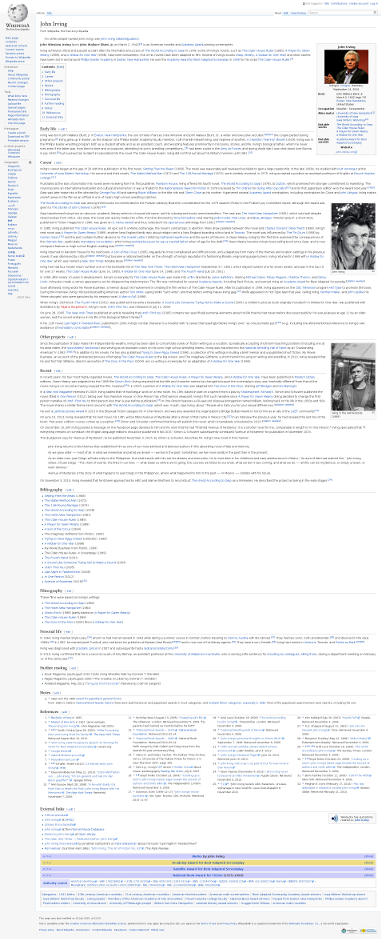
This web page has several features indicating that John Irving is a writer we want to have in our set. Let’s introduce and discuss six of them:
-
The first sentence says that John Irving is a novelist and screenwriter:
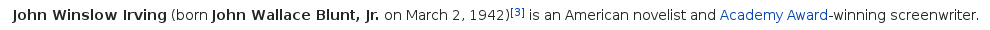
-
The table of contents lists a bibliography:

-
The infobox on the right has an occupation property with values “Novelist” and “Screenwriter”:
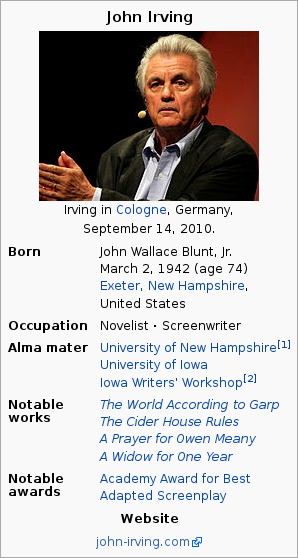
-
Scrolling down, the John Irving template assembles a list of works by the author:

-
Scrolling down further, we find a list of categories, among them 20th-century American novelists, 21st-century American novelists, American feminist writers, and American male screenwriters:

-
In addition, by looking at the wiki source code of the page we realise that the infobox uses the writer template:

To leverage one of these features to automatically identify John Irving (and others, of course) as a writer, we have to answer these questions:
- Which of the information is universally available (i.e., in different language versions)?
- Which of the information is available through DBpedia or Wikidata?
- How widespread is the information used?
- How easy is it to actually use the information to identify writers?
We will discuss these questions tomorrow in the 2nd part of this blog post.

