In the first post of this 2-part series we introduced six features of Wikipedia pages on writers that might help us figure out if those pages are, in fact, about (literary) writers. Today we want to discuss which of these features are actually suited to reliably identify writers in Wikipedia. Our goal is to build a set of contributors to world literature that we can further investigate (and keep updated, as Wikipedia evolves). Instead of providing a conclusive answer here, this post will concentrate on observations that could eventually help to implement an approach for the automated identification of literary writers in Wikipedia.
First Sentence
- This feature is available throughout all language versions.
- The automated analysis of sentences requires some sophisticated natural language processing which should also be available for different languages. The quality of such approaches highly depends on the chosen language.
- The results are quite ambiguous, since even within one language version there is no standardised way to describe writers.
- DBpedia has implemented a framework for fact extraction which could potentially extract this information.
Table of Contents

- At first sight, a “Bibliography” section seems to be the prevalent way to list original works of an author in the English Wikipedia. But not all writers have one. Also, the name of the section is not consistent (e.g., in the article on John Milton it is called “Works”). “Bibliography” can also refer to a list of secondary literature (see the article on Gabriel García Márquez).
- Albeit its ambiguity, finding the “Bibliography” headline in the wiki source code is easy. Finding equivalent headings in other language versions would require some effort, though.
- It is unclear if and how this feature is used in other language versions.
- The section structure of articles is currently not provided by DBpedia.
Occupation Property
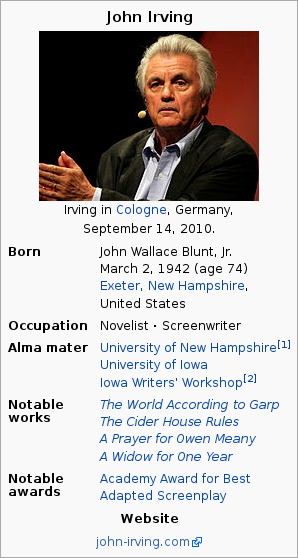
- This property often contains several (ambiguous) values without further distinctions (“writer”, “novelist”, “poet”, etc.).
- Values of this property are highly language-dependent, it is rather difficult to make use of it in a cross-language environment.
- Not all language editions permit infoboxes for writers (among others, the German edition).
- If available, the infobox properties are extracted by DBpedia. They can be found in the infobox properties dataset and in the mapping-based properties dataset. The latest dataset contains this information in the infobox properties dataset:
<http://dbpedia.org/resource/John_Irving> <http://dbpedia.org/property/occupation> "Novelist"@en .
<http://dbpedia.org/resource/John_Irving> <http://dbpedia.org/property/occupation> "Screenwriter"@en .
List of Works

- In our example page on John Irving, this feature was implemented using a specific John Irving template. Other popular/canonised writers also have that kind of template, yet in general, this feature is not very widespread.
- There are categories for such templates, like Category:Novelist navigational boxes, making it easy to check which writers have such a template.
- Apparently, there are only two other language editions with such a template, Romanian and Farsi.
Categories

- The category graph is quite inconsistent. In particular, it is not a tree. (cf. O. Medelyan, D. Milne, C. Legg, I. H. Witten (2009), Mining meaning from Wikipedia)
- As we have seen, there are many categories that could be used to identify a person as a writer, but they do not cover all writers. Categories higher up the hierarchy (e.g., Writers by century) would cover more writers but due to some dubious subcategories (e.g., Baconian theory of Shakespeare authorship) also cover pages that are definitely not about writers (e.g., Honorificabilitudinitatibus).
- For instance, starting the traversal at the Writers by Century category in the English version, the set would contain persons like Winston Churchill and Leonardo da Vinci, while omitting writers like Gertrude Stein and Heinrich Heine.
- Each language version has its own category structure. Thus, the effort of identifying corresponding categories and removing false positives would need to be repeated for each language.
- Articles are usually assigned to several categories which would enable identification of writers which also had other occupations.
- DBpedia provides the article_categories dataset which contains the assignment of categories to articles and the skos_categories dataset which contains the category graph.
Writer Template

- Not all language editions have or use such template. E.g., the German Wikipedia does not permit the writer template and, thus, its page on Johann Wolfgang von Goethe lacks an infobox.
- Each page can be assigned to exactly one template, which means that some persons do not have a writer template, although we’d clearly like to have them in our set. This includes Franz Kafka (neutral person template) and Umberto Eco (tied to a philosopher template).
- The association of Wikipedia pages to templates has been extracted
by DBpedia in the instance types dataset.
The value is provided in the
typeproperty. For John Irving, it contains the following information:
<http://dbpedia.org/resource/John_Irving> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://dbpedia.org/ontology/Writer> .
Conclusion
Summarising the above findings in a table, we get the following result:
| feature | language editions | usage within language editions | DBpedia dataset | effort | ambiguity |
|---|---|---|---|---|---|
| first sentence | all | all | - | high | high |
| table of contents | all | some | - | low | medium |
| occupation property | some | many | infobox properties | medium | high |
| list of works | few | few | - | low | low |
| categories | all | many | article categories and skos categories | high | high |
| writer template | some | many | instance types | low | low |
Given the large variety of properties the different features have, it is quite difficult to devise an approach to identify writers on Wikipedia that works across different language versions. This 2-part blog post was a preliminary introduction to get a sense of the problem. We proposed and applied a solution that basically works across different language versions in a still unpublished paper (on which we will keep you posted) and will introduce a pragmatic and manageable set that can be used for a variety of purposes in one of our next blog posts.

